Posts
-
Reducing Lambda latency by 76% with AWS Lambda Power Tuning
Optimizing AWS Lambda memory capacity can decrease customer-facing latencies by up to 2-5 times without significantly increasing hardware costs, but can take some trial and error.
The AWS Lambda Power Tuning tool can be used to determine the optimal memory capacity for any Lambda function within minutes, and can be set up in a few button clicks.
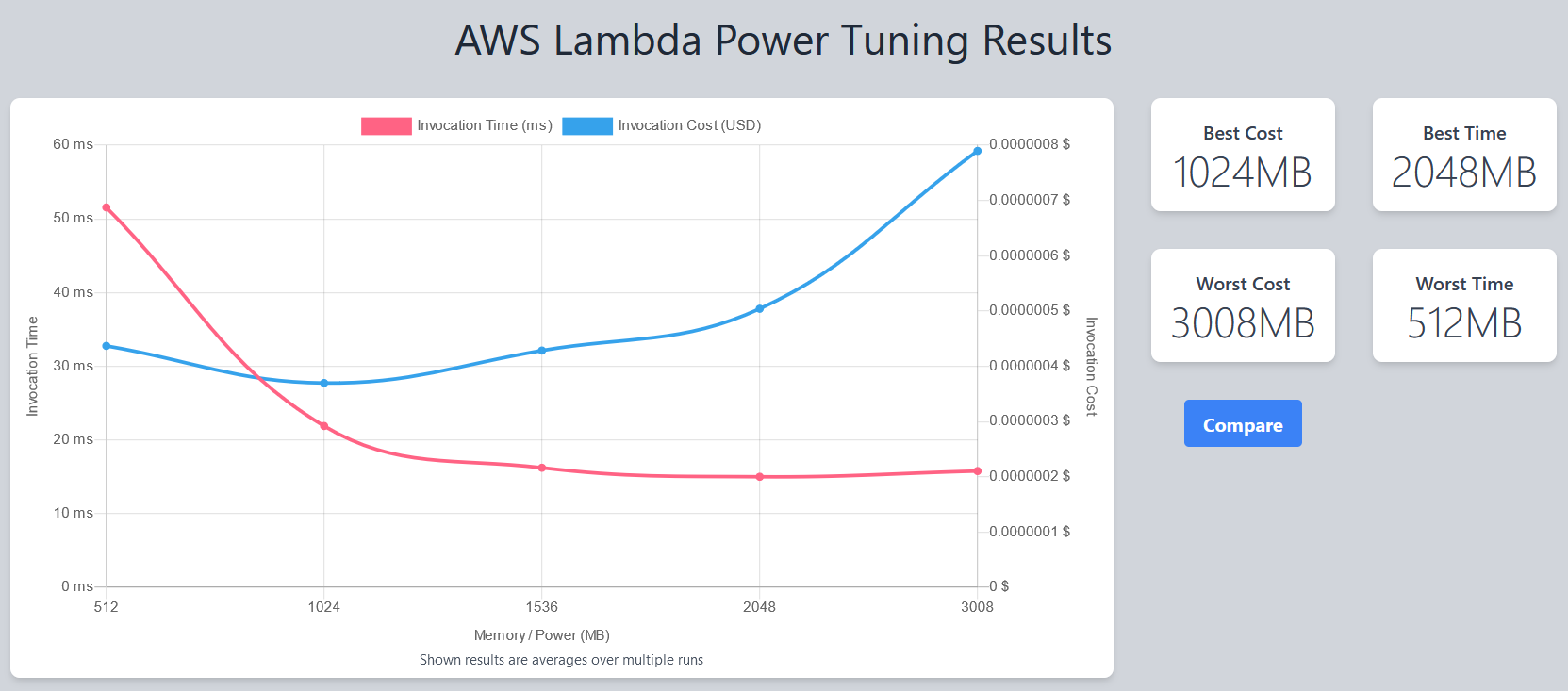
-
Serializing and deserializing DynamoDB pagination tokens to support paginated APIs
When using AWS's Java 2.x SDK, DynamoDB scan and query responses provide pagination tokens in a String to AttributeValue Map object, which represents the primary key of the last processed DynamoDB item. You can then pass this value as the "exclusive start key" for the next query to get the next page of results.
When your service retrieves all pages of results locally, this isn't a problem. However, when you want to provide a paginated API backed by DynamoDB, you'll need to convert this attribute value map into a format that can be passed over HTTP, AKA "serialize" the object into a string.
-
Concurrency from single host applications up to massively distributed services
This post will describe several levels of concurrency, how they're commonly applied, and pros and cons of each approach.
Many distributed services now start with multi-host clusters for reliability and scalability reasons, so that any given host can be replaced without impacting customer service, and additional hosts can be added as needed.
-
Process for designing distributed systems
In this post I'll step through my process for designing distributed systems, with example questions and artifacts associated with each step.
We will take the following steps to design a new service:
1. Validate whether this service needs to exist
2. Clarify business requirements
3. Estimate scale
4. Define system interfaces and data models
5. Define data flow and storage
6. Define high-level system components
7. Design individual components
The artifacts of each step can be validated with stakeholders to ensure we're on the right track before continuing. They collectively add to a design document that can be referred to both while building the service, and afterwards to understand its inner workings.
-
Choosing between AWS compute services
When building a new service in AWS, it can be difficult to decide between all the available compute services. In this post I’ll give a brief overview of the main options and describe how I compare and choose between them for a given project.
-
AWS caching options
AWS provides several ways to cache data depending on your use case and infrastructure requirements. In many cases, you don’t need to invent the wheel and can use a fully-managed solution that does not require significant code changes.
By caching at the appropriate layer, you can optimize latencies while minimizing unnecessary load to your backend services, allowing you to scale at a reasonable cost.
-
AWS S3 bucket creation dates and S3 master regions
While working on functionality that depended on AWS S3 bucket ages, I noticed that published bucket CreationDate values didn’t always reflect when the buckets were created.
For example, when I called the S3 ListBuckets API a few minutes after updating a bucket access policy, the CreationDate value returned for that bucket was the time that I had modified the policy rather than the time that I had created the bucket. This was also reproduced when using the AWS CLI via the
aws s3api list-bucketscommand. -
Choosing a logging library for Kotlin or Java AWS Lambda functions
There are a lot of logging libraries to choose from when writing AWS Lambda functions in Kotlin or Java. Since Kotlin is fully interoperable with Java, Kotlin projects have access to both Kotlin-based and Java-based logging libraries.
This post compares some of the major options and evaluates which are most suitable for Lambda functions.
subscribe via RSS